RESTful APIs Guide
convertDocAnnToPdf
This API converts and returns documents to PDF and embeds annotations if provided.
- URL: “/api/v1/convertDocAnnToPdf”
- Action Name: convertDocAnnToPdf
- Type: POST
- Consumes: application/json
- Produces: application/json
- Request Body:
An object with the following attributes:- fileData
- Type: String
- Description: Base64 encoded file data.
- annData
- Type: String
- Description: Base64 encoded annotation JSON data.
{ "fileData": "BASE64 encoded file data", "annData": "Optional BASE64 Ann JSON Data" } - fileData
- Response Body:
Returns string type having base 64 encoded pdf file data.{ "pdfFileData": "BASE64 encoded pdf file data" }
convertToPdf
This API converts and returns documents as PDF.
- URL: “/api/v1/convertToPdf”
- Action Name: convertToPdf
- Type: POST
- Consumes: application/json
- Produces: application/json
- Request Body:
An object with one attribute:- fileData
- Type: String
- Description: Base 64 encoded file data.
{ "fileData": "BASE64 encoded file data", } - fileData
- Response Body:
Returns string type having base 64 encoded pdf file data.{ "pdfFileData": "BASE64 encoded pdf file data" }
merge
This API combines one or more files. If the files are not PDF, they will be automatically converted to PDF provided they are part of the supported format list.
- URL: “/api/v1/merge”
- Action Name: merge
- Type: POST
- Consumes: application/json
- Produces: application/pdf
- Request Body:
An object with one attribute:- files
- Type: Array of file objects
- Description: Each file object includes two attributes:
- url [optional]: If URL is not provided then b64Data must be provided.
- Type: String
- Description: The URL of the file that needs to be merged.
- b64Data [optional]: If b64Data is not provided then the URL must be provided.
- includePages
- Type: String
- Description: Filter for pages to be included in the merge operation. Possible values can be:
- “all”: To include all pages of the document during the merge.
- Hyphen-separated page range (i.e. 1-2)
- Selected pages using comma (i.e. 1,2)
- url [optional]: If URL is not provided then b64Data must be provided.
The payload snippet with URL:
{ "files": [{ "url":"url to the document", "includePages": "all" }, { "url":"url to the document", "includePages": "1-2" }, { "url":"url to the document", "includePages": "1,2" }] }The payload snippet with base64 file data:
{ "files": [{ "b64Data":"base64 encoded document content", "includePages": "all" }, { "b64Data":"base64 encoded document content", "includePages": "1-2" }, { "b64Data":"base64 encoded document content", "includePages": "1,2" }] } - files
- Response Body: Returns the final pdf stream of the document.
mergeMP
This API combines multiple files into a PDF.
- URL: “/api/v1/mergeMP”
- Action Name: mergeMP
- Type: POST
- Consumes: Multipart Form Data
- Produces: application/pdf
- Request Body:
Form Data Attributes:- files:
- Type: BLOB
- Description: Binary file data
Note: Multiple files can be provided with the same “files” key.
- includePages:
- Type: String
- Description: Filter for pages to be included in the merge operation. Possible values can be:
- “all”: To include all pages of the document during the merge.
- Hyphen-separated page range (i.e. 1-2)
- Selected pages using comma (i.e. 1,2)
Note: The parameter needs to use a ‘;’ separator for each multipart file.
For Example: If there are 3 multipart files being merged then “all;1-2;1,3”
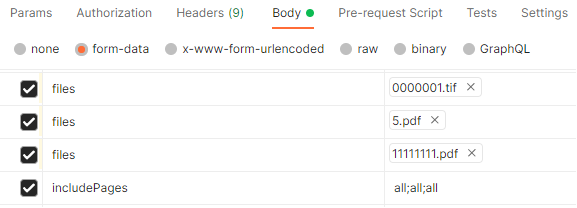
- files:
- Response Body:
Returns the final pdf stream of the document.
mergexfdf
This API combines a PDF with its XML based Adobe Pdf annotations (i.e. xfdf) into a PDF with all annotations embedded in it.
- URL: “/api/v1/mergexfdf”
- Action Name: mergexfdf
- Type: POST
- Consumes: application/json
- Produces: application/pdf
- Request Body:
An object with one attribute:- files:
- Type: A file object
- Description: The file object includes two attributes:
- docurl:
- Type: String
- Description: The URL of the pdf file that needs to be merged.
- xfdfurl:
- Type: String
- Description:The URL of the xfdf file that contains annotations.
- docurl:
The payload snippet with URL:
{ "files": { "docurl":"http://localhost:8080/tiff/aninpm/sample.pdf", "xfdfurl": "http://localhost:8080/tiff/aninpm/sample.xfdf" } } - files:
- Response Body:
Returns the final pdf stream of the document.
split
This API splits a file into two or more than two parts.
- URL: “/api/v1/split”
- Action Name: split
- Type: POST
- Consumes: application/json
- Produces: application/json
- Request Body:
An object with the following attributes:- url
- Type: String
- Description: URL to the file to split.
- splitByPgNumbers
- Type: Array of numbers
- Description: The page number from where to create a new document.
{ "url":"https://researchtorevenue.files.wordpress.com/2015/04/1r41ai10801601_fong.pdf", "splitByPgNumbers": [3,7] } - url
- Response Body:
Returns an array of strings, each string holds the base64 encoded pdf data for each document part.[ "BASE64 encoded data of part", "BASE64 encoded data of part" ]
extractPages
This API extracts one or more pages from a file as a new document.
- URL: “/api/v1/extractPages”
- Action Name: extractPages
- Type: POST
- Consumes: application/json
- Produces: application/pdf
- Request Body:
An object with the following attributes:- url
- Type: String
- Description: URL to the file to extract pages from.
- extractPgNumbers
- Type: Array of numbers
- Description: The page numbers that need to be extracted.
{ "url":"https://researchtorevenue.files.wordpress.com/2015/04/1r41ai10801601_fong.pdf", "extractPgNumbers": [3,5,7] } - url
- Response Body:
Returns the final pdf stream of the document.
applyWatermark
This API adds a watermark to all the pages of a provided file.
- URL: “/api/v1/applyWatermark”
- Action Name: applyWatermark
- Type: POST
- Consumes: application/json
- Produces: application/pdf
- Request Body:
An object with the following attributes:- fileType
- Type: String
- Description: MimeType of the input file.
- fileData
- Type: String
- Description: base64 encoded file content.
- wmText
- Type: String
- Description: Text to be applied as a watermark.
{ "fileType": "application/pdf" "fileData":"base64 encoded file content", "wmText": "APPROVED" } - fileType
- Response Body:
Returns the final pdf stream of the document.
cropPage
Crops a section of page from a document.
- URL: “/api/v1/cropPage”
- Action Name: cropPage
- Type: POST
- Consumes: application/json
- Produces: application/json
- Request Body:
An object with the following attributes:- baseURL
- Type: String
- Description: base64 encoded file content.
- pageNo
- Type: String
- Description: Comma separated page numbers to be cropped.
- X
- Type: String
- Description: Start X position of ROI to crop.
- Y
- Type: String
- Description: Start Y position of ROI to crop.
- W
- Type: String
- Description: Width of ROI to crop.
- H
- Type: String
- Description: Height of ROI to crop.
{ "baseURL": "base64 encoded file content", "pageNo": "1,3,5", "X": "10", "Y": "10", "W": "100", "H": "100", } - baseURL
- Response Body:
Returns the final pdf stream of the cropped document.
compareDocsMP
Compares 2 documents for changes in text and other document objects such as graphics, images, annotations etc.
- URL: “/api/v1/compareDocsMP”
- Action Name: compareDocsMP
- Type: POST
- Consumes: MULTIPART_FORM_DATA_VALUE
- Produces: application/json
- Request Body:
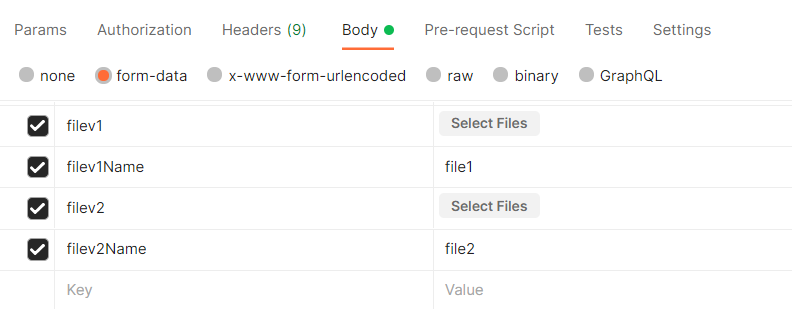
Form Data Attributes:- filev1
- Type: BLOB
- Description: Binary file data.
- filev1Name
- Type: String
- Description: Name of filev1.
- filev2
- Type: BLOB
- Description: Binary file data.
- filev2Name
- Type: String
- Description: Name of filev2.
- filev1
Response Body: Returns the final pdf stream of the cropped document.
Compare JSON Object
It is an object type having the following attribute:
- compareDocumentInformation
- Type: Array of Array Objects
- Description: Contains an array of Compare Result Objects.
{
"compareDocumentInformation": [
[
{
"annotInfo": [],
"imageInfo": [
{
"baseValue": "276",
"baseText": "191",
"testValue": "Width | Height | Byte Count | Suffix",
"changed": true
},
],
"pageNumber": 0,
"textInfo": [
{
"baseValue": "Times New Roman (not embedded, using fallback font 'TimesNewRomanPSMT')",
"baseText": "Times New Roman (not embedded, using fallback font 'TimesNewRomanPSMT')",
"testValue": "Font | Font Size | Fill Colorspace | Fill Color",
"changed": true
},
],
"graphicsInfo": [
{
"baseValue": "Stroke",
"baseText": "Stroke",
"testValue": "Paint Operator | Position & Size | ",
"changed": true
},
]
}
]
]
}
Compare Result Objects
An object having the following attributes:
- annotInfo
- Type: Array of Compare Difference Object
- Description: Contains the difference found in the annotations of the two documents.
- imageInfo
- Type: Array of Compare Difference Object
- Description: Contains the difference found in the images of the two documents.
- pageNumber
- Type: Number
- Description: Describes the page number where the difference is found between the two documents.
- textInfo
- Type: Array of Compare Difference Object
- Description: Contains the difference found in the text of the two documents.
- graphicsInfo
- Type: Array of Compare Difference Object
- Description: Contains the difference found in the graphics of the two documents.
Compare Difference Object
It is an object type having the following attributes:
- baseValue:
- Type: String
- Description: It stores the original value.
- baseText:
- Type: String
- Description: It stores the updated value.
- testValue:
- Type: String
- Description: It defines the type of the value.
- changed:
- Type: Boolean
- Description: It stores the boolean value true or false.
redactFile
Redacts a specified area or words or predefined macros.
- URL: “/api/v1/redactFile”
- Action Name: redactFile
- Type: POST
- Consumes: application/json
- Produces: application/json
- Request Body:
An object with the following attributes:- fileData
- Type: String
- Description: base64 encoded PDF file content.
- fileType
- Type: String
- Description: Set to application/pdf.
- regularExpressions [OPTIONAL]
- Type: Array of String
- Description: Contains redaction attributes. It is mandatory if “redactRectangles” is not provided. The string can be the name of the available MACRO of SMART redaction.
- MACROS
- SSN
- AGE
- Date
- Phone
- DOB
- ACCOUNT NUMBER
- CREDIT CARD
- GENDER
- RACE
- POLICY NUMBER
- PASSPORT NUMBER
- DRIVER LICENSE
- NAME
- STATE
- BETWEEN
- ADDRESS
- Word
- HTTP_URL
- ZIP_CODE
- US_CURRENCY
- <token_name>_sep_<token_value>
Available tokens and their values:
- redactWord – <phrase to redact>_colorSep_<color_value_as_number>_Wordsep__colorSep_<color_value_as_number>_Wordsep_;
- selectall – NONE
- wholeWord – NONE
- caseSensitive – NONE
- MACROS
- redactRectangles [OPTIONAL]
- Type: Array of Redact Rectangle Objects.
- Description: Array of JSON Rectangle Objects. It is mandatory if “regularExpressions” is not provided.
- fileData
Response Body: Returns the final pdf stream of the redacted document.
Redact Rectangle Objects
It is an object type having the following attributes:
- pageNumber
- Type: Number
- Description: Describes the page number on which redaction is performed.
- X
- Type: Number
- Description: Start X position of redact area.
- Y
- Type: Number
- Description: Start Y position of redact area.
- W
- Type: Number
- Description: Describes the width of the redacted area in pixels.
- H
- Type: Number
- Description: Describes the height of the redacted area in pixels.
- username
- Type: String
- Description: The name of the user.
- redactionTag
- Type: String
- Description: The reason for redaction.
{
pageNumber:1,
"X": 10,
"Y": 10,
"W": 100,
"H": 100,
"username": " demo",
"redactionTag":" reason for redaction",
}
ocrFile
OCR’s the provided input image file.
- URL: “/api/v1/ocrFile”
- Action Name: ocrFile
- Type: POST
- Consumes: application/json
- Produces: application/json
- Request Body:
An object with the following attributes:- fileData
- Type: String
- Description: base64 encoded image content.
- fileData
Response Body: Returns an OCR Job Creation Object.
OCR Job Creation Object
It is an object type having the following attributes:
- Status
- Type: String
- Description: It will describe the status of the OCR.
- PageNumber
- Type: Number
- Description: Describes the page number on which OCR is performed.
- JOBID
- Type: String
- Description: It is the UNIQUE JOB ID assigned to the OCR job and can be used later to track the progress of OCR via the OCR job status API.
{
Status: "OCR_IN_PROGRESS | OCR_FINISHED | OCR_FAILED | OCR_PROCESSING",
PageNumber:1,
JOBID: " UNIQUE JOB ID"
}
ocrjobstatus
Provides the status of an ongoing OCR job.
- URL: “/api/v1/ocrjobstatus”
- Action Name: ocrjobstatus
- Type: GET
- Produces: application/json
- Query Arguments:
- jobId
- Type: String
- Description: UNIQUE JOB ID returned by ocrFile API.
- jobId
Response Body: Returns an OCR Job Status Object.
OCR Job Status Object
- Status
- Type: String
- Description: It describes the status of the OCR.
{
Status:" OCR_IN_PROGRESS | OCR_FINISHED | OCR_FAILED | OCR_PROCESSING",
}
ocrjobData
Get the OCR data for a job that has finished.
- URL: “/api/v1/ocrjobData”
- Action Name: ocrjobData
- Type: POST
- Consumes: application/json
- Produces: application/json
- Request Body:
An object with the following attributes:- jobId
- Type: String
- Description: UNIQUE JOB ID returned by ocrFile API.
- jobId
Response Body: Returns an OCR Job Complete Object.
OCR Job Complete Object
It is an object having the following attributes:
- Status
- Type: String
- Description: It describes the status of the OCR.
- ocrData
- Type: Array of OCR Result Objects
- Description: It will describe the OCR results.
{
Status:" OCR_IN_PROGRESS | OCR_FINISHED | OCR_FAILED | OCR_PROCESSING",
ocrData:[]// ARRAY of OCR Result Objects
}
OCR Result Object
It is an object type having the following attributes:
- boundingBox
- Type: String
- Description: It contains the java.awt.Rectangle object.
- confidence
- Type: Number
- Description: It indicates the OCR confidence level for recognizing a word correctly between 1-100.
- text
- Type: String
- Description: The word that has been found after OCR is done.
{
boundingBox:"java.awt.Rectangle[x=103,y=284,width=243,height=20]",
confidence:1-100,
text: "SOMETEXT"
}